两台实体机器4个虚拟机节点的Hadoop集群搭建(Ubuntu版)
安装Ubuntu
Linux元信息
- 两台机器,每台机器两台Ubuntu
- Ubuntu版本:ubuntu-22.04.3-desktop-amd64.iso
- 处理器数量2,每个处理器的核心数量2,总处理器核心数量4
- 单个虚拟机内存8192MB(8G),最大磁盘大小30G
参考链接
-
清华大学开源软件镜像站
-
虚拟机(VMware)安装Linux(Ubuntu)安装教程
具体步骤
-
把下载好的iso文件保存到一个位置

-
开始在VMware安装Ubuntu
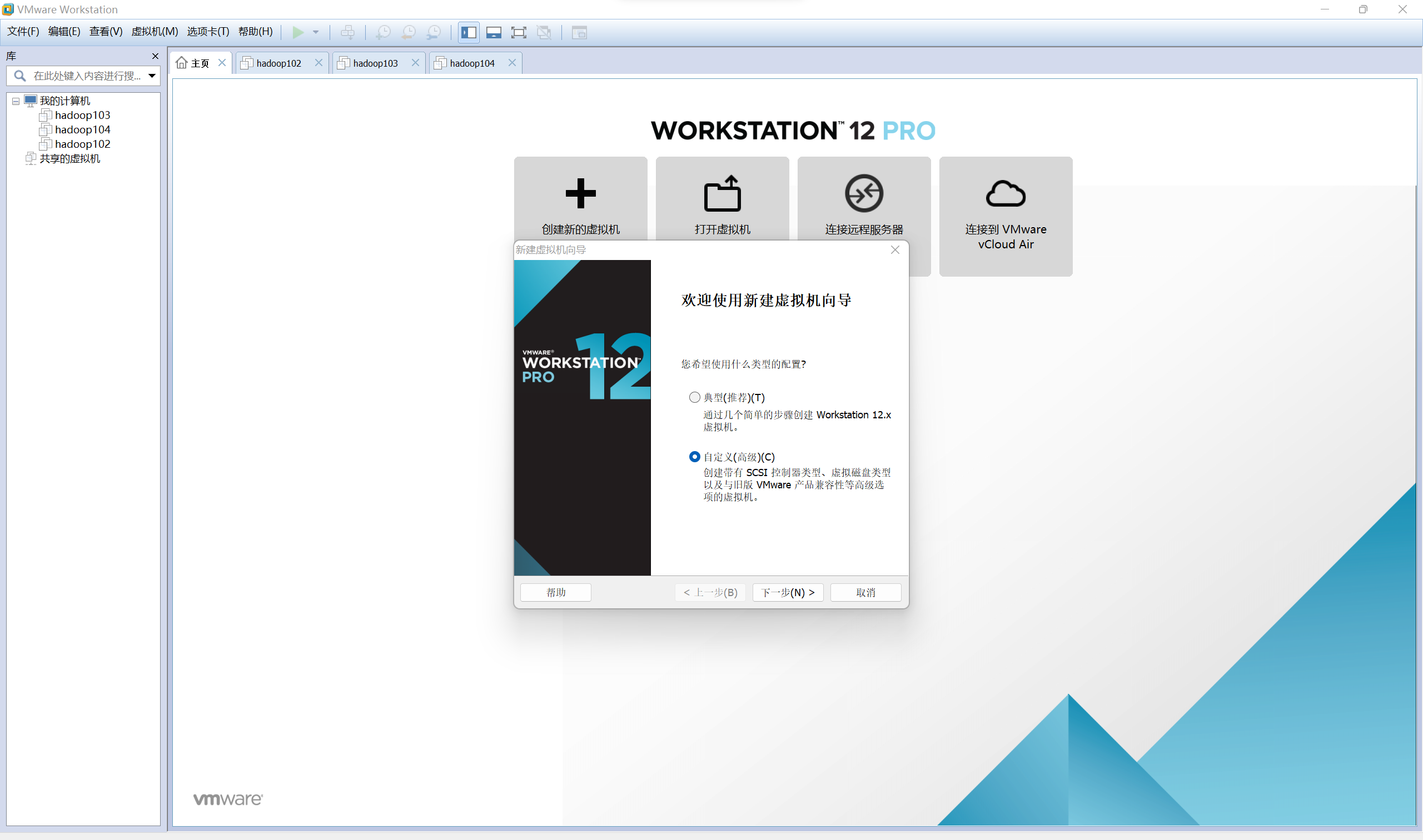
-
选择网络类型(图片错了,应该是“桥接网络”,详见“配置虚拟机网络”)

-
指定磁盘容量

-
设置镜像文件
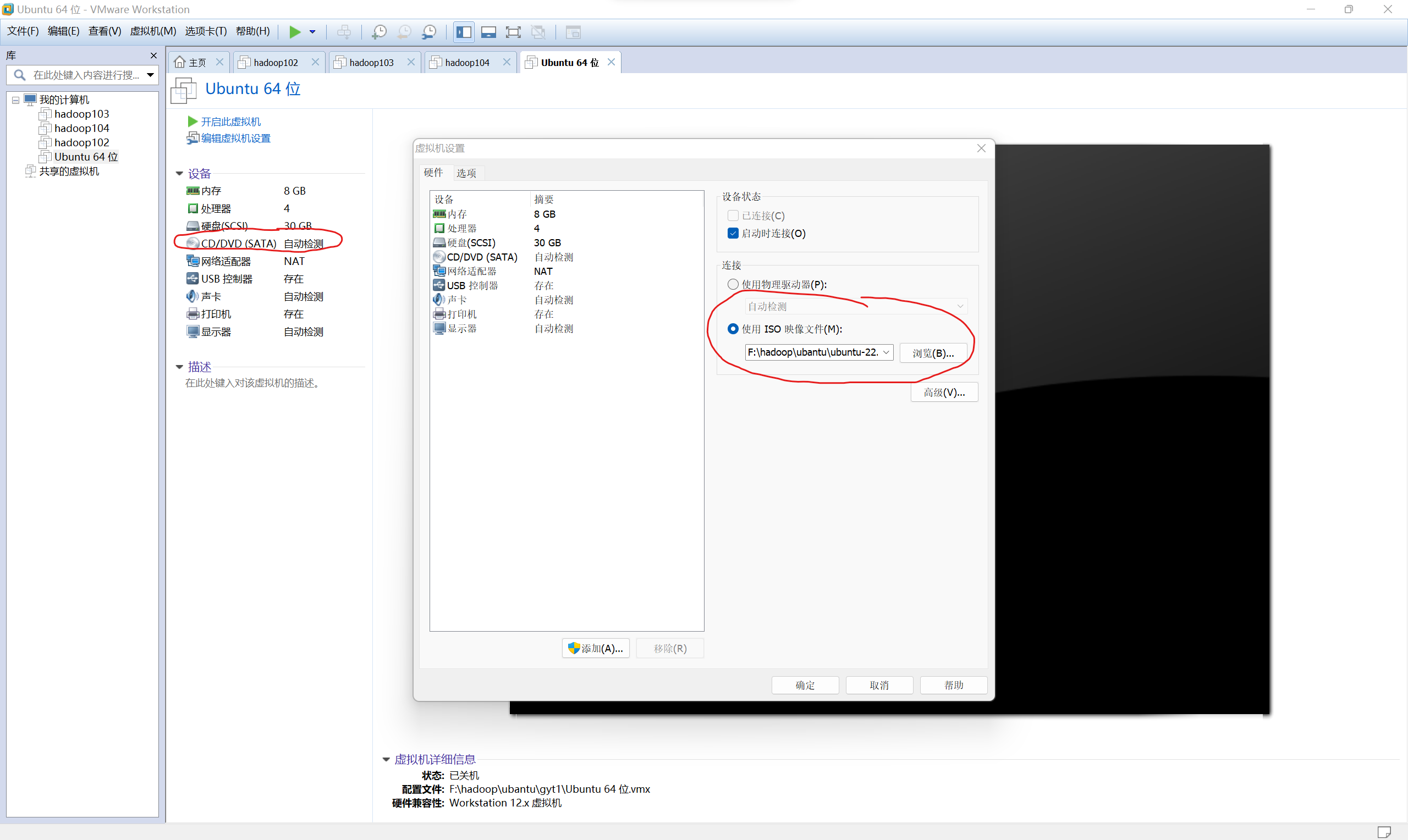
-
开始安装Ubuntu

配置虚拟机网络
配置桥接模式
-
查看宿主机WLAN硬件配置信息

-
打开VMware中的虚拟网络编辑器,根据宿主机WLAN硬件配置如下信息

设置虚拟机静态IP
防止每次开机随机IP,导致无法连接到其他虚拟机
-
切换root用户(第一次切换root用户需要配置root密码)
sudo passwd -
打开01-network-manager-all.yaml文件(网卡配置文件)
vim /etc/netplan/01-network-manager-all.yaml -
删除原内容,复制粘贴如下信息(根据实际情况更改)
# Let NetworkManager manage all devices on this system network: ethernets: ens33: dhcp4: false addresses: [192.168.139.101/24] routes: - to: default via: 192.168.139.92 nameservers: addresses: [8.8.8.8] version: 2 -
在宿主机的cmd中运行ipconfig命令查看网络信息,如下图所示:

-
根据第四步更改第三步的部分信息
- via:宿主机的默认网关
- addresses:前三位和宿主机默认网关保持一致,后一位自己随便设置(但要避免和已有ip重复)
安装Hadoop
Hadoop元信息
-
统一用户名:hjm,密码:000000
-
四台虚拟机分别为gyt1,gyt2,hjm1,hjm2
-
四台虚拟机用桥接模式,连接一台手机的热点,虚拟机ip如下:
hjm1:192.168.139.101
hjm2:192.168.139.102
gyt1:192.168.139.103
gyt2:192.168.139.104
-
集群部署规划
hjm1 hjm2 gyt1 gyt2 HDFS NameNode、DataNode DataNode SecondaryNameNode、DataNode DataNode YARN NodeManager NodeManager NodeManager ResourceManager、NodeManager
配置用户sudo权限
配置以后,每次使用sudo,无需输入密码
-
用sudo权限打开sudoers文件
sudo vim /etc/sudoers -
增加修改sudoers文件,在%sudo下面新加一行(这里以hjm用户为例)
# Allow members of group sudo to execute any command %sudo ALL=(ALL:ALL) ALL hjm ALL=(ALL) NOPASSWD: ALL
创建目录并更改权限
-
创建module和software文件夹
sudo mkdir /opt/module sudo mkdir /opt/software -
修改 module、software 文件夹的所有者和所属组均为hjm用户
sudo chown hjm:hjm /opt/module sudo chown hjm:hjm /opt/software
Ubuntu查看、安装和开启ssh服务
-
查看ssh服务的开启状态,如果开启,则可以跳过这一部分
ps -e|grep ssh -
安装ssh服务
sudo apt-get install openssh-server -
启动ssh服务
sudo /etc/init.d/ssh start
注意:
当你用ssh软件(这里默认是Xhell 7)连接时,不要用root用户连,ssh默认 不能用root直接连,除非修改配置文件
安装JDK
-
用xftp工具将jdk导入到opt目录下面的software文件夹下面
-
解压jdk到opt/module目录下
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/ -
配置jdk环境变量
(1)新建/etc/profile.d/my_env.sh 文件
sudo vim /etc/profile.d/my_env.sh(2)添加以下内容
#JAVA_HOME export JAVA_HOME=/opt/module/jdk1.8.0_212 export PATH=$PATH:$JAVA_HOME/bin(3)保存后退出,source 一下/etc/profile 文件,让新的环境变量 PATH 生效
source /etc/profile(4)测试jdk是否安装成功
java -version
安装Hadoop
-
用xftp工具将hadoop导入到opt目录下面的software文件夹下面
-
解压hadoop到opt/module目录下
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/ -
配置hadoop环境变量
(1)打开/etc/profile.d/my_env.sh 文件
sudo vim /etc/profile.d/my_env.sh(2)在 my_env.sh 文件末尾添加如下内容
#HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop-3.1.3 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin(3)保存后退出,source 一下/etc/profile 文件,让新的环境变量 PATH 生效
source /etc/profile(4)测试hadoop是否安装成功
hadoop version
修改配置文件
cd到$HADOOP_HOME/etc/hadoop目录
core-site.xml
<configuration>
<!-- 指定 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hjm1:8020</value>
</property>
<!-- 指定 hadoop 数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置 HDFS 网页登录使用的静态用户为 hjm -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>hjm</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<!-- nn web 端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hjm1:9870</value>
</property>
<!-- 2nn web 端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>gyt1:9868</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<!-- 指定 MR 走 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>gyt2</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CO
NF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAP
RED_HOME</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
workers
hjm1
hjm2
gyt1
gyt2
克隆虚拟机
-
在hjm1和gyt1的两台宿主机上分别克隆出hjm2和gyt2

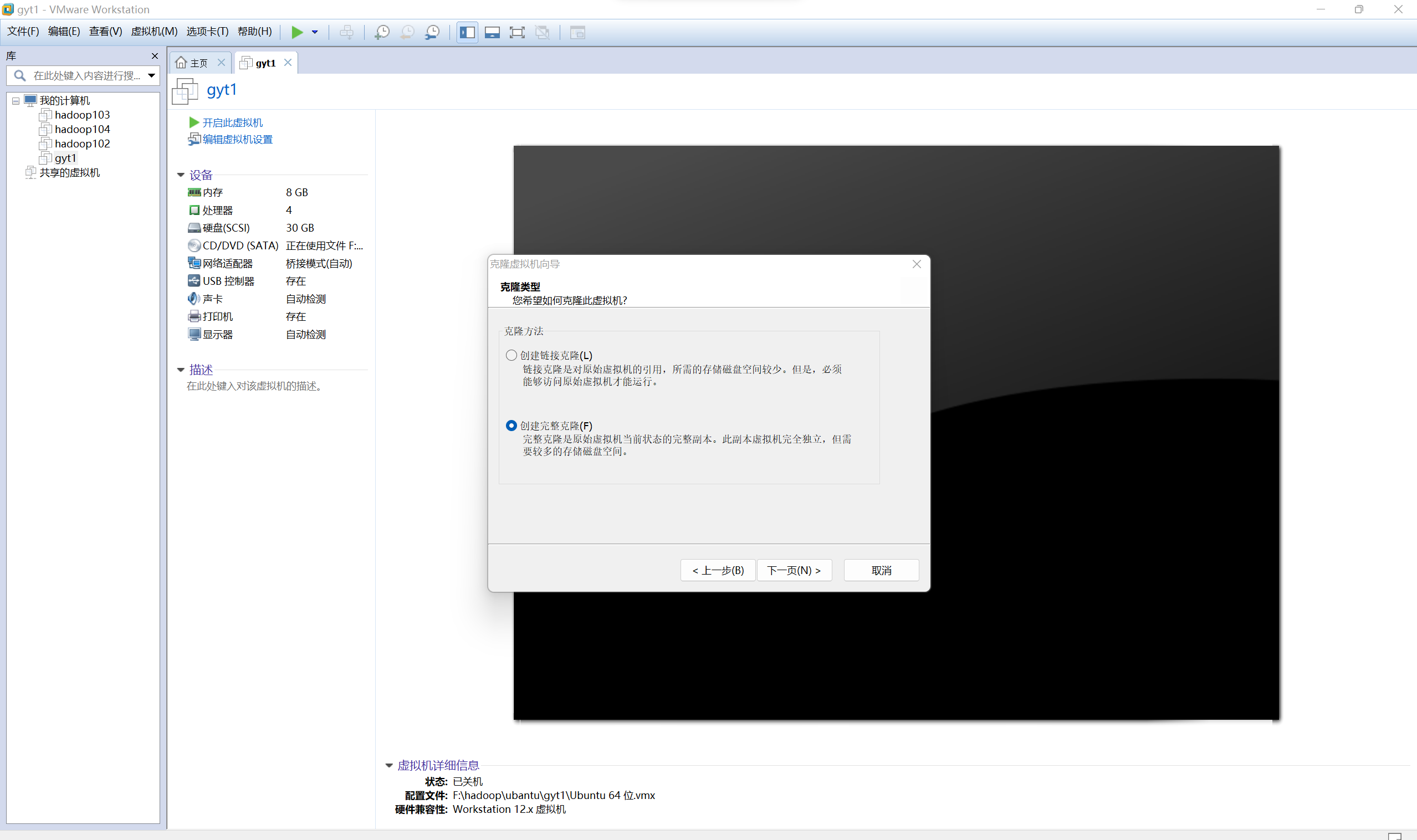
-
按照“配置虚拟机网络-设置虚拟机静态IP”的方式,配置hjm2的ip为192.168.139.102,gyt2的ip为192.168.139.104
-
改每台虚拟机的ubuntu映射文件,这里以gyt2为例
127.0.0.1 localhost # 127.0.1.1 gyt2 记得删除这一行 192.168.139.101 hjm1 192.168.139.102 hjm2 192.168.139.103 gyt1 192.168.139.104 gyt2 -
修改四台虚拟机的主机名分别为hjm1,hjm2,gyty1,gyt2
sudo vim /etc/hostname -
重启虚拟机
ssh免密登录
- 分别要配置16种免密登录,如下图所示

-
切换hjm用户,cd到~/.ssh,生成公钥和私钥
ssh-keygen -t rsa -
将公钥复制到目的机上,这里以hjm1举例
ssh-copy-id hjm1
xsync集群分发脚本
-
在/home/hjm/bin目录下创建xsync文件
-
在该文件中编写如下代码
#!/bin/bash #1. 判断参数个数 if [ $# -lt 1 ] then echo Not Enough Arguement! exit; fi #2. 遍历集群所有机器 for host in hadoop102 hadoop103 hadoop104 do echo ==================== $host ==================== #3. 遍历所有目录,挨个发送 for file in $@ do #4. 判断文件是否存在 if [ -e $file ] then #5. 获取父目录 pdir=$(cd -P $(dirname $file); pwd) #6. 获取当前文件的名称 fname=$(basename $file) ssh $host "mkdir -p $pdir" rsync -av $pdir/$fname $host:$pdir else echo $file does not exists! fi done done -
修改脚本xsync具有执行权限
chmod +x xsync -
测试脚本
xsync /home/atguigu/bin -
将脚本复制到/bin中,以便全局调用
sudo cp xsync /bin/ -
在客户端电脑(默认windows)配置映射
(1)windows + R
(2)输入drivers,回车
(3)进入etc文件夹
(4)编辑hosts文件
192.168.139.101 hjm1 192.168.139.102 hjm2 192.168.139.103 gyt1 192.168.139.104 gyt2
测试hadoop
-
格式化NameNode
如果集群是第一次启动,需要在 hadoop102 节点格式化 NameNode(注意:格式化 NameNode,会产生新的集群 id,导致 NameNode 和 DataNode 的集群 id 不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化 NameNode 的话,一定要先停止 namenode 和 datanode 进程,并且要删除所有机器的 data 和 logs 目录,然后再进行格式化。)
hdfs namenode -format -
在hjm1上启动hdfs
sbin/start-dfs.sh -
在gyt2上启动yarn
sbin/start-yarn.sh -
Web 端查看 HDFS 的 NameNode
-
Web 端查看 YARN 的 ResourceManager
-
测试结果
(1)datanode
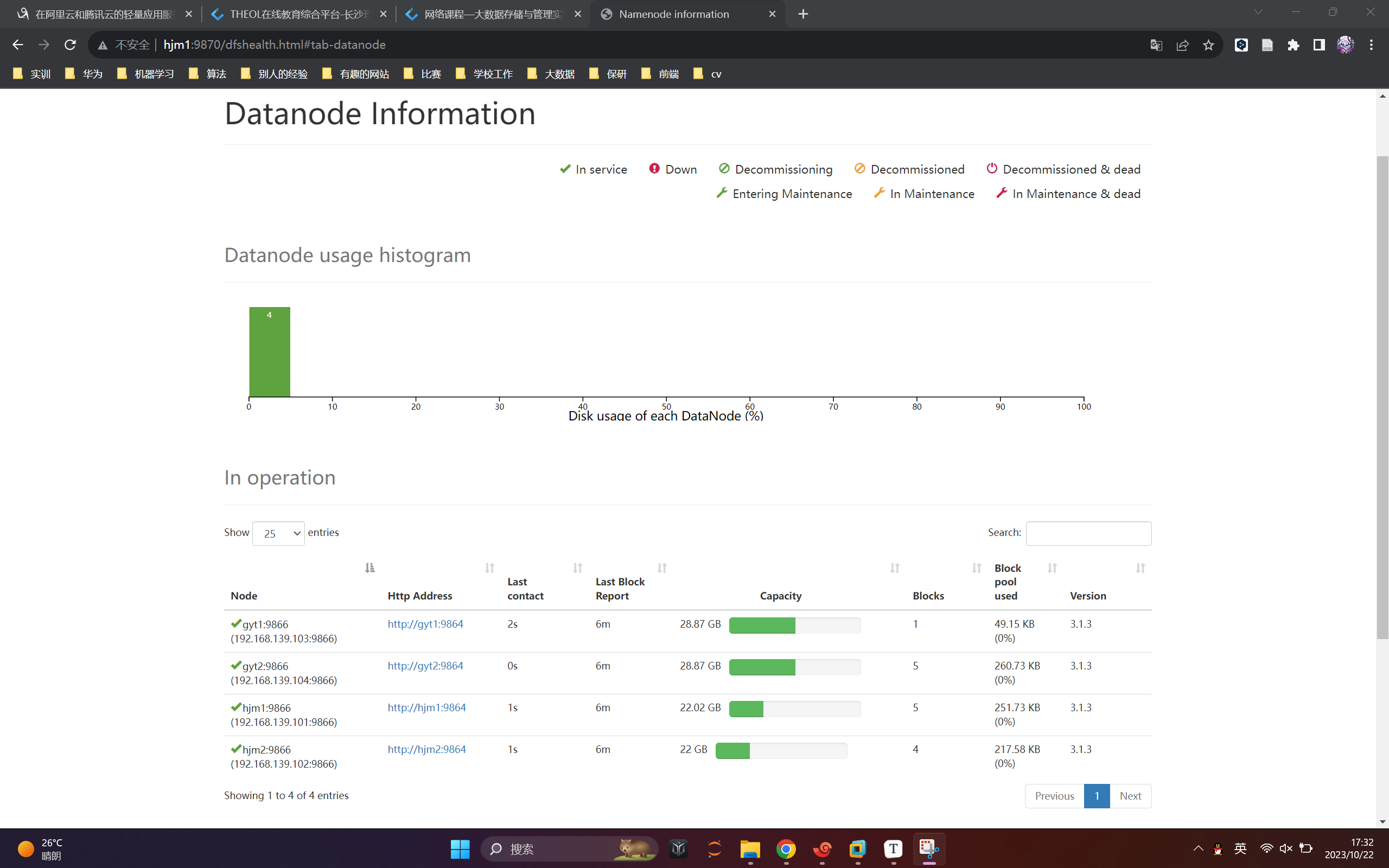
(2)Yarn

(3)WordCount
